
Supervised vs. Unsupervised Learning: Breaking Down the Key Differences
Understanding how machines learn with and without labeled data.

Machine learning is transforming the way we interact with technology, from personalized recommendations on streaming services to self-driving cars. But how do these intelligent systems learn? The two most common types of machine learning are supervised learning and unsupervised learning. Understanding their differences is essential for anyone curious about AI, whether you're a beginner or an expert.
What is Unsupervised Learning?
Unsupervised learning is like learning without a teacher. Imagine you move to a new country and see unfamiliar fruits at a market. Without labels, you start grouping them based on similarities, like shape, color, and texture.
Similarly, in machine learning, unsupervised learning works with data that has no labels. The system finds patterns, structures, or relationships in the data on its own.
How It Works:
The algorithm receives an unlabeled dataset.
It looks for patterns, similarities, or clusters within the data.
The system organizes data into meaningful groups or reduces complexity without prior knowledge of the correct answers.
Real-World Examples of Unsupervised Learning:
Customer Segmentation: Businesses use it to group customers based on their buying behavior.
Anomaly Detection: Banks use it to detect fraudulent transactions that don’t fit usual spending patterns.
Recommender Systems: Streaming platforms like Netflix group users with similar interests to recommend relevant movies and shows.
What is Supervised Learning?
Supervised learning is like learning with a teacher. Imagine you’re learning to identify different fruits. A teacher shows you an apple and says, "This is an apple." They do the same for bananas, oranges, and other fruits. After seeing many labeled examples, you start recognizing fruits on your own.
In machine learning, this process works similarly. A system is given a dataset where each example has an input (features) and an output (label). The goal is to learn the relationship between inputs and outputs so that the system can predict labels for new, unseen data.
How It Works:
The algorithm is fed a labeled dataset containing input-output pairs.
It learns to map inputs to correct outputs using statistical techniques.
Once trained, it can make predictions on new, unseen data based on learned patterns.
Real-World Examples of Supervised Learning:
Spam Detection: Email services use supervised learning to distinguish between spam and non-spam emails by learning from labeled examples.
Image Recognition: Systems like Google Photos can recognize people in pictures by training on labeled face images.
Medical Diagnosis: AI models can predict diseases based on labeled medical records.
Supervised Learning Categories:
Classification – The goal is to categorize data into predefined labels (e.g., distinguishing cats from dogs in images).
Regression – The goal is to predict continuous values (e.g., predicting house prices based on features like size and location).
Unsupervised Learning Categories:
Clustering – Grouping similar data points together (e.g., segmenting customers based on shopping habits).
Dimensionality Reduction – Simplifying large datasets while preserving key information (e.g., compressing high-resolution images without losing essential details).
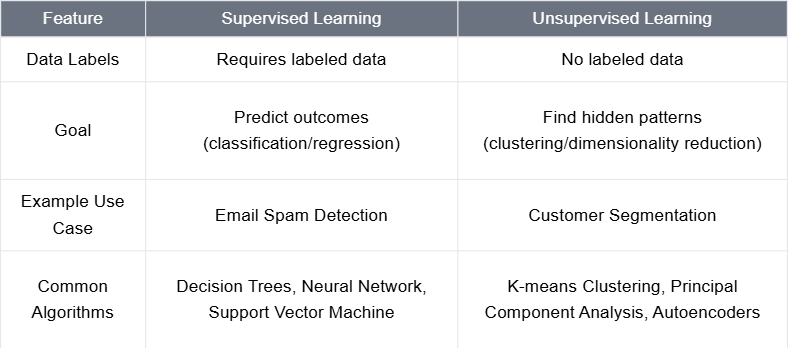
Key Differences Between Supervised and Unsupervised Learning
Which One Should You Use?
It depends on the problem you’re trying to solve:
If you have labeled data and want to make predictions, use supervised learning.
If you don’t have labels and want to discover patterns, use unsupervised learning.
Final Thoughts
Both supervised and unsupervised learning play crucial roles in AI and machine learning. Supervised learning is great for tasks where past knowledge exists, like identifying spam emails. On the other hand, unsupervised learning is powerful when exploring unknown patterns, like segmenting customers.